
In store pt. 1, I gave a general overview of the systems's architecture, and went into a bit of detail over the choice of indexing structure. In this post, I want to do a deep dive on the philosophy and design of the various data formats that the system uses over the network, in memory, and on persistent storage.
This won't be definitive documentation for any of the formats that I describe, and the project is still under active development, so all of these are subject to change. That being said, hopefully I can give a good sense of the goals and ideas driving the current design.
a data movement problem
I can't stress enough that this is the core design area of the entire system. The shape of the data we use in our systems, and the protocols we use to input and output that data, are the definitive ceiling for the performance and quality of the work that our systems can do.
In most cases, this work is solving a data transformation problem. A video game takes mouse movements and key presses as inputs, and transforms them into pixels on the screen, an LLM takes a sequence of tokens as inputs, and transforms them into a probability distribution of the next token, etc. These systems function effectively by, and are fundamentally tasked with, transforming their inputs into their outputs.
store is a bit different, we have a data movement problem to solve. The fundamental task of the system is to move bytes back and forth between network connections and persistent storage as fast and efficiently as possible while upholding our correctness guarantees. There is no transformation that needs to happen to fulfill the task of the system, and in general, we want to minimize transformations as much as possible. Unless these transformations drastically aid our ability to move data, they are just unnecessary work.
This isn't anything new either, lots of systems solve data movement problems. A simple web server, for example, needs to solve the problem of moving html files from local storage into the user's browser. The browser is tasked with transforming this html into pixels on the screen, all the server needs to care about is getting the bytes where they need to go.
To solve this problem well, we need our format design to support two core pieces. First, we need a degree of universality to the shape of our data. In an ideal world, we should be able to just copy bytes between storage and network buffers directly, with no transformation. Second, we need to be able to support on demand parsing. We want to be able to, arbitrarily at any time, transition between thinking about logical types, and raw byte buffers. When we need to control our data movement in some structured way, we can get the information necessary to do so, and the rest of the time, we can just think about moving raw bytes around efficiently. This means our parsing needs to be very fast, and incremental. Most of the time, we should be able to just read a few bytes, jump around to some offsets, and hand the rest of the data off to the next component of the system.
ops
The core data format in the system is called an "op". They are simultaneously descriptions of data movement, and the container for data itself. Ops come in four broad categories:
- reads: ops which describe data movement from storage to network
- writes: ops which describe data movement from network to storage
- macros: compositions of reads and writes materialized on the server
- txn ctrl: ops which direct transactions (such as a commit or abort)
That's it. All work done by the system is driven through these four kinds of ops.
All ops are prefixed by a flags byte, which contains metadata and type information about the op. This allows us to have individual subtypes of ops (reads, writes, etc) cover a wide variety of logical data movement patterns without using too many bytes, and keeps our parsing fast by helping us minimize branching. Here's what the layout of the flags byte looks like for each of our ops:
the first two bits represent the main type of the op:
00 <- read
01 <- write
10 <- macro
11 <- txn ctrl
the following 6 bits are type specific flags, for example:
for reads and writes, the next two bits are used to specify a "key structure",
00 <- single key
01 <- range
10 <- batch
for txn ctrl, the next two bits are used to specify the specific txn command
00 <- commit
01 <- abort
etc ...
This means reads and writes can represent any data movement pattern that falls into their semantics (data moving in purely one direction). A read can be a single point read, or a range scan. A write can be a single key put, or a batch delete, etc.
For transaction control, the entire op is just this flags byte, nothing else needs to be specified (at least for now, this may change if we get more complex and varied transaction semantics in the future). The rest of the ops have a payload following the flags byte, with a layout specific to the type of op and the flags set. This payload has a layout optimized for the specific nature of the op, but will generally contain some combination of keys and values. Keys and values are both just arbitrary byte sequences, with the following structures:
key
[ len (u16) ][ bytes ... ]
val
[ val type (u8) ][ maybe len (u32) ][ maybe bytes ... ]
Keys are pretty simple, just a length prefixed byte sequence. Values typically have a similar structure, with a larger maximum length, but unlike keys, are prefixed by an additional type byte. This byte specifies, well, the type of the value. Specifically this is used to represent deletes/tombstones with a 0 val type, and can be extended to represent other kinds of values (such as a pointer to a large off page value, or a lock on a key, etc), similar to our flags byte. Having a separate val type also means we can have store function as a set, as opposed to a map, by writing values with a length of 0.
Lets tie everything together by looking at a few simple ops:
GET
[ 00000000 ][ key len ][ key bytes ... ]
PUT
[ 01000000 ][ key len ][ key bytes ... ][ 1 ][ val len ][ val bytes ... ]
DEL
[ 01000000 ][ key len ][ key bytes ... ][ 0 ]
COMMIT
[ 11000000 ]
macros
It's worth noting that we can represent any valid data movement pattern with just reads, writes, and transaction semantics. For efficiency purposes though, it may make sense to capture some logical description of a sequence of reads and writes, so that we can send the whole thing to the server in one go, and avoid having to do a network roundtrip for each of the individual read/write ops. This is where macros come in.
Macros are descriptions of sequences of reads and writes which get materialized on the server. For example, an "increment" macro would contain a key and an "increment by" value, and on the server would be expanded to something like:
MACRO
[ flags ][ key ... ][ inc val ... ]
EXPANDED
old val = [ read key ]
[ write key, old val + inc val ]
Macros also have specific semantics for how and when they're materialized (as a quick aside, this isn't trivial to do correctly, I'll probably end up writing a full post on macros in the future). For example, a compare-and-swap macro and a conditional write macro may expand to the same exact sequence of reads and writes,
current = [ read, key ]
if current == expected
[ write, key, new ]
but that sequence would be materialized at different times and in different ways. A CAS would materialize at request time, so that the response to the op could specify whether or not the CAS succeeded, but a conditional write macro would just get written verbatim into a page, and materialized on demand during reads, or eventually fully materialized during a compaction.
These materialization semantics also let us do some interesting things that typically are out of scope for this kind of system. For example, a "watch" macro could materialize into a read for a key whenever a write to that key is committed, effectively allowing us to send live push-based updates to a client, all within the normal mechanics of the system.
For now, macros are fairly minimal, and hard coded into the system, but eventually, the plan is to expand this into a comprehensive set, and potentially allow for user defined macros as well.
network protocol
The network protocol for store is a fairly simple custom tcp protocol. It's design is driven by the needs of the common use case for store. Most of the time, store will be used as a storage subcomponent in a larger distributed system, for example as storage for a larger fully fledged SQL database, or as metadata storage for an object store, etc. This means we'll experience a kind of "funneling" effect, where we receive a large workload through a relatively small number of connections and nodes (for example, a distributed sql database would have a handful of query nodes funneling all of it's storage work from the outside world into a store instance). This means our protocol needs to be able to handle a large number of transactions per connection, with maximum pipelining.
To pull this off, we treat the tcp streams as a never ending sequence with the following format:
[ txn_id (u64) ][ op ... ][ txn_id ][ op ... ][ txn_id ][ op ... ] etc ...
Here, transaction ids are u64s generated by the client which are scoped to an individual network connection. store composes more complex ids internally based on these, so the client only has to guarantee that an id is unique for a given connection (a simple per connection incrementing counter should do the trick). Transactions are implicitly began when the first op for a given transaction id is received by store, and, for a given transaction id, results are sent back to the client in the order the ops were received, so no request-response matching is needed. This structure also means we can break free of the request-response pattern trivially when it doesn't apply (for example, streaming chunks of a range scan, or indicating to a client that a transaction was aborted for some internal reason).
Response "ops" (naming things is hard, sue me 🤷) use the rightmost bit in the flags byte to represent whether or not the request op succeeded (0 is success, 1 is error). If a response op indicates an error, it is followed by a one byte error code, and (if configured) an error message. Here are a few request-response pairs to get a feel for things:
SINGLE KEY READ
[ 00000000 ][ key ] (request)
[ 00000000 ][ val ] (successful response)
^- same val as before, a "tombstone" == "not found"
SINGLE KEY WRITE
[ 01000000 ][ key ][ val ] (request)
[ 01000000 ] (successful response)
^- no other data needed
TXN COMMIT
[ 11000000 ] (request)
[ 11000001 ][ 100 ][ "write-write conflict on key user:123" ] (err response)
^-----^- errored with code 100 (write-write conflict)
pages
Pages in store are entirely a logical and in memory construct (we'll see how they're represented on persistent storage next). Physically in memory, they're represented by simple byte buffers with the following layout:

Conceptually, I like to think of this buffer as having a "top" and "bottom", where the top is the 0th index, and the bottom is the capacity-th index. At the bottom, we have a simple footer with 3 u64s, a left page id, a right page id, and a length for the entries section. The page ids in leaf pages are pointers to siblings, facilitating range scans. In inner pages, the right page id is the rightmost child pointer of the page, and the left page id is set to u64::MAX, which indicates that the page is an inner page. The entries section is directly above the footer, and contains compacted read only data. This looks roughly like a typical btree page layout, with less metadata since we don't need to do in place updates or manage free space, and in general we can go pretty hard on the optimizations here since it's read only.
Finally, above the entries section is the ops section. This is a reverse chronological sequence of ops. Crucially, these are the same exact bytes as the ops coming in over the network (with some additional pre/ap-pended metadata like timestamps for managing transactions). We can copy bytes directly from a network buffer to a page with zero transformation in between. These ops are not exclusively network requests, however. For example, inner pages will contain write ops describing splits and merges to their child pages. In general, this pattern is incredibly useful, and can be extended to represent any logical modification to a page in the system, or even the entire index.
Currently, compaction is done inline with writes, and is treated similarly to splits and merges in traditional btrees. When a page's buffer doesn't have room to accept a new op, the page is compacted. Then, if there still isn't room for the op, the page is split. Just like a typical btree, this process can cascade up to the root. While there are certainly optimizations to be done here around when and how much to compact, this default behavior does have some nice properties. Namely, we get a natural spreading out of incremental compaction work. Pages are much smaller than something like an LSM tree level, so the compaction itself is fairly cheap, and the rate at which compaction happens for a given page is directly related to how frequently it is written to. There is some potential for suboptimal compaction patterns here, for example during a large ingest with no reads, the compaction will just slow things down, and we don't get much of a benefit from doing the work. For regular day to day operations however, this pattern is pretty close to optimal, and the skew in the compaction work generally is the behavior we want. If a page is super hot, we get a huge benefit from compacting it frequently, and if it's cold, we don't have to worry about it.
storage
The file for an index is made of three distinct sections: a header, an offset table, and a data blocks section. The header isn't very exciting, pretty much just what you'd expect (a magic number, version, configuration parameters, etc). We'll talk about the offset table briefly in a bit, but it'll help to first understand how the data blocks work.

Logically, the data blocks section is treated as a circular buffer of fixed length "blocks", with a head and a tail. In memory, we have a flush buffer of the same length, and when a page is evicted, any unflushed data from that page is appended to the flush buffer as a page "chunk". Chunks have a short header with a length, and a "next" offset. This next offset indicates the offset in the file of the previous page flush. When we flush a newly compacted page, the next offset is set to 0, indicating there are no more chunks for the current state of this page (I'll describe how this is used when we talk about the offset table).
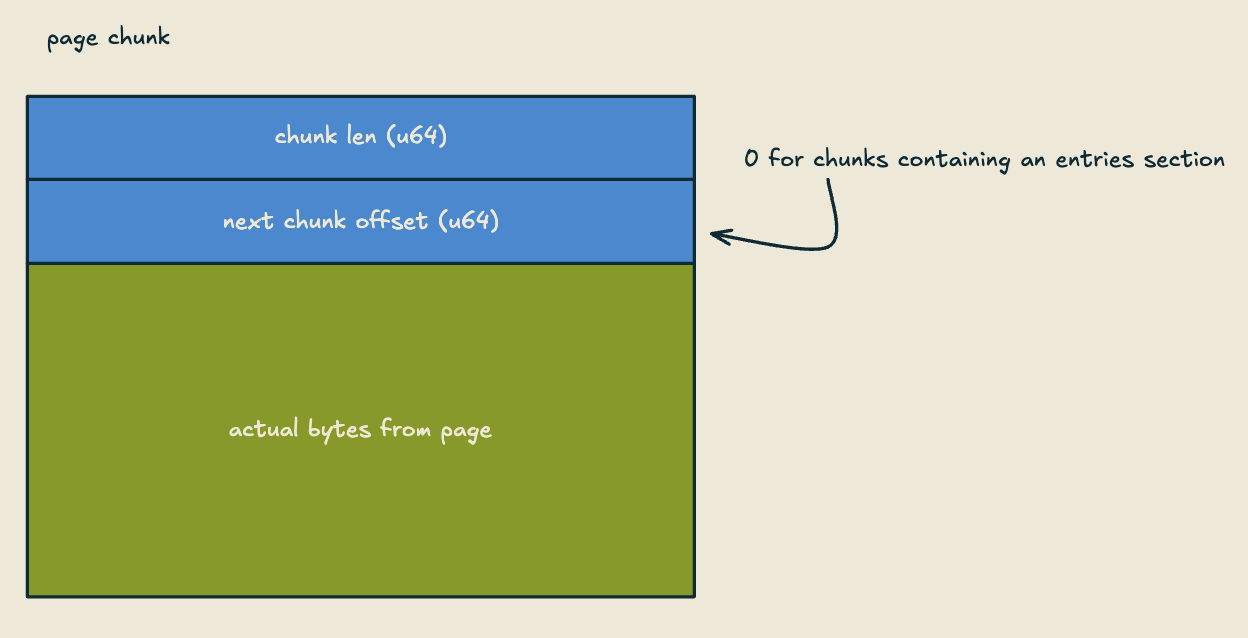
When the flush buffer fills up, we simply append it to the head of the data blocks section, and update the head. This means, when a page is compacted, we may have data on disk for that page that is garbage, since we're only appending data, and not updating in place. To handle this, we have a separate garbage collection system that periodically reads blocks which are likely to contain mostly garbage (we know this by updating metadata when we compact a page), copying over any non-garbage chunks to the flush buffer, and throwing away the rest. When we gc the block at the tail of the data blocks section, we update the tail. This is pretty much exactly what the bw-tree/llama papers do, and is essentially the same way log structured file systems work.
For reading from the file, we need some way to know where in the data blocks section the page is, this is where the offset table comes in. The offset table is just a sequence of u64 pairs, the first indicating a page id, and the second indicating the offset in the file of the most recent page chunk. We load the entire table into memory at startup, this in memory representation is updated when pages are flushed, and periodically we write out the in memory representation to the offset table section (this interacts heavily with WAL checkpointing, so I'll talk about it more in a future post when I cover transactions).
Since all of our IO is done asynchronously via io_uring, we maintain a priority queue of pages to be read, and issue reads for full blocks based on this queue. When a read for a block is finished, we grab any chunks we need from that block, and update the priority queue accordingly. We continue reading in a page until we find a chunk with a 0 next offset, which means we've read in the entire page (the page chunks essentially form a linked list). This setup generally means that we may have to issue multiple read ios for a given page, but we get some throughput back by having full block reads make progress on multiple pages, and given that our system is designed to work with SSDs, this read-write amplification trade off is well worth it.
potpourri
compression
One elephant in the room I haven't touched on yet is compression. This is one of the data transformations that actually does make our data movement significantly more efficient, and is therefore generally worth doing. The two main places where general purpose compression fits in naturally are network streams and storage data blocks.
For network streams, we won't always want to do compression. If we're running on a fast network connection (same data center, maybe even physically connected), the cpu overhead of compression could outweigh the benefits we get going over the wire, so this will definitely be an optional and configurable setting. We'll specifically want streaming compression in this setting. We don't really have any kind of frame in our network protocol (other than individual ops, which are way too small for general purpose compression), so we want a compression algorithm that handles a continuous stream of bytes effectively. Zstd set to a low level/fast mode (1-3 ish) is a natural fit here. It gets great compression levels and has a very fast decoding. LZ4 is another option, with worse compression levels but even faster encoding/decoding. LZ4 doesn't quite fit in with streaming compression as well, but it could work. In general, we’ll probably end up wanting to standardize on a single general-purpose compression algorithm across the system, to avoid conversion overhead and maximize opportunities to "just copy the bytes", so the specific algorithm used will really depend on what profiling shows, and the optimizations we find when implementing this.
For storage compression, the main place I'm seeing as the right fit would be full data block compression. Since blocks are quite large, we'll get fantastic compression ratios, and since we're paying an io cost anyway whenever we interact with blocks, the cpu overhead of the compression itself should be fairly well hidden. The one hiccup here is garbage collection. Since we don't actually need to read much of the bytes when doing gc, adding the overhead of decompression full blocks just to copy some of the data over into a new block is a bit wasteful, so potentially, page chunk level compression would be a better fit, again this is a question best answered by profiling.
Lastly, entries sections of pages are potentially good candidates for non general purpose compression. RocksDB, for example, uses prefix compression inside of their PlainTables. This will be massively implementation specific, and may not be the right setup for the way we want to use our indexing structure. In general we're targeting massively batched work wherever we can, and as such, our search within pages will likely end up looking more like a series of matrix multiplications than a sequential scan or binary search (which is what we currently do), so non general purpose compression could end up not really fitting in well with our system.
the $SYS keyspace
This isn't exactly related to data formats, but it relies heavily on the ops mechanics that I've introduced in this post, so I think it's worth talking about here.
Logically, store manages a single keyspace for the entire database. For organizational purposes, or use case specific needs, some interface niceties can be added on top of this by essentially treating subsets of the keyspace as some kind of logical unit. FoundationDB has something similar which they refer to as "directories", I'll probably end up just calling them keyspaces, but the general idea is that you have a certain prefix be treated as a unit, so for example any key starting with users/ would belong to the "users" keyspace, and you can put stuff like schemas and configuration parameters specific to the keyspace in a users/.config key, etc etc, you get the idea.
Building on top of this kind of functionality, store treats the $SYS keyspace as special. All system data and administrative functionality live here. This means logs, metrics, configuration, and administrative commands are all driven through the $SYS keyspace, using the same reads, writes, and macros as the rest of the system. Want to pull the logs from the last week? [ read, range = $SYS/log/(now - 7 days) .. ], want to set the buffer pool size for shard 3 to 6 gigabytes? [ write, key = $SYS/shard/3/cfg/buf_pool_size, val = 6GB ], want to be notified when transactions per second drops below 10,000? [ watch macro, key = $SYS/metrics/tps/live, threshold = lt(10000) ]. This pattern gets really powerful really quick.
It also means that interacting with store in an administrative capacity becomes a fully "programmable" environment, with the same transaction mechanisms as the rest of the system, which can be leveraged to do some pretty dynamic things. For example, the following sequence of ops could be sent to store from a cron job:
[ write, key = $SYS/cmd/vacuum, val = "start" ]
[ watch macro, key = $SYS/metrics/rps/live, threshold = gt(1000) ]
if watch macro triggered before vacuum finishes
[ txn_ctrl, abort ]
else
[ txn_ctrl, commit ]
This would start an expensive vacuum operation, and watch the "requests per second" metric to see if it goes over a certain threshold. If the system starts experiencing a spike in work, the watch macro will be triggered, and the cron job cancels the vacuum operation (aborts the "transaction") to free up more resources to handle the workload spike, and otherwise it goes through with completing the vacuum.
That's the current state of store's data format. There will probably be plenty of updates and tweaks as things develop, but the underlying philosophy is the same: solve the data movement problem. Next up: transactions!